8月28日,苹果在arXiv发布新论文,介绍新一代多模态基础模型MobileCLIP2及其背后的多模态强化训练机制,同天在GitHub、Hugging Face上开源了模型的预训练权重和数据生成代码。
MobileCLIP2专为零样本分类和检索任务设计,推理延迟在3-15毫秒之间,参数规模在50~1.5亿不等。

此前基于Transformer的大型编码器存在较大内存和延迟开销,为在移动设备上部署带来的挑战。基于此,苹果2023年11月发布端侧多模态大模型MobileCLIP,通过多模态强化训练方法改进模型在端侧的部署效果,MobileCLIP2是其改进多模态强化训练方法后的升级版模型。
论文中提到,与上一代模型相比,MobileCLIP2-B在图像分类基准数据集ImageNet-1k上的零样本准确率提高了2.2%。其模型变体MobileCLIP2-S4在iPhone 12 Pro Max上测得的零样本准确率可对标参数规模更大的SigLIP-SO400M/14。
此次其改进的多模特训练训练机制采用了改进的教师监督(Teacher Supervision)与字幕数据(Caption Data)来提升零样本性能。
与此同时,在移动端,该训练机制支持多模态模型直接在移动、边缘设备上部署,实现零样本检索/分类,具有极低的延迟和内存占用。
目前,MobileCLIP2所有模型变体的预训练权重均已公开,开发者可以直接部署和进行基准测试。苹果还发布了数据生成代码,开发者可以基于此使用分布式可扩展处理创建具有任意教师的新强化数据集。
模型的预训练权重链接:
https://github.com/apple/ml-mobileclip
强化训练的数据生成代码链接:
https://github.com/apple/ml-mobileclip-dr
GitHub链接:
https://github.com/apple/ml-mobileclip
Hugging Face链接:
https://huggingface.co/collections/apple/mobileclip2-68ac947dcb035c54bcd20c47
论文地址:
https://arxiv.org/html/2508.20691v1
01.iPhone 12 Pro Max可跑强调可复现性、可扩展性MobileCLIP2的核心优势在于实现了相比现有模型参数规模更小、延迟更低,且不牺牲泛化能力、准确性的性能。
在零样本性能方面,MobileCLIP2-S4在iPhone 12 Pro Max上测得的准确率与SigLIP-SO400M/14相当,但参数量为后者的1/2;在延迟方面,MobileCLIPS2-S4的表现优于DFN ViT-L/14,延迟约为后者的约40%。
零样本指标提升可以使模型在未经过特定任务、类别或场景的训练时,无需额外标注数据微调,就能直接将预训练学到的通用知识迁移到未知任务中。
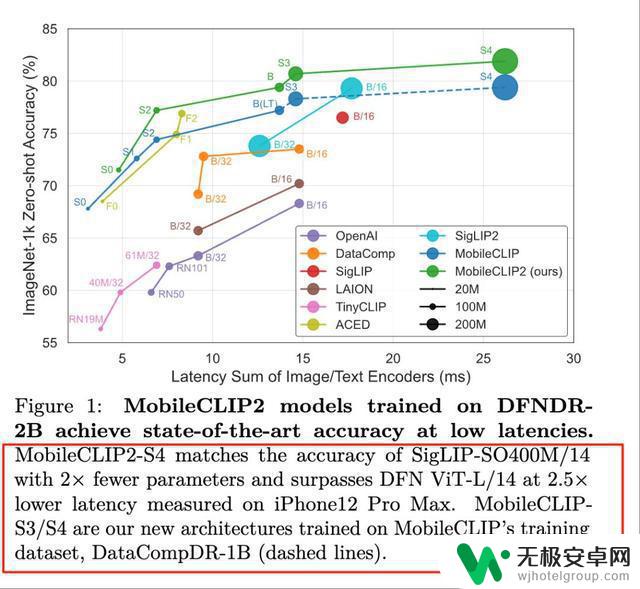
图像分类基准数据集ImageNet-1k上的基准测试结果
MobileCLIP2系列模型在不同延迟条件下,38个数据集上平均性能均为最佳。
从下面的测评中看到,MobileCLIP2-S2与SigLIP2-B/32的参数规模差距达到4倍,但性能相当,MobileCLIP2-S4与DFN ViT-L/14相比,推理速度提高2.5倍。
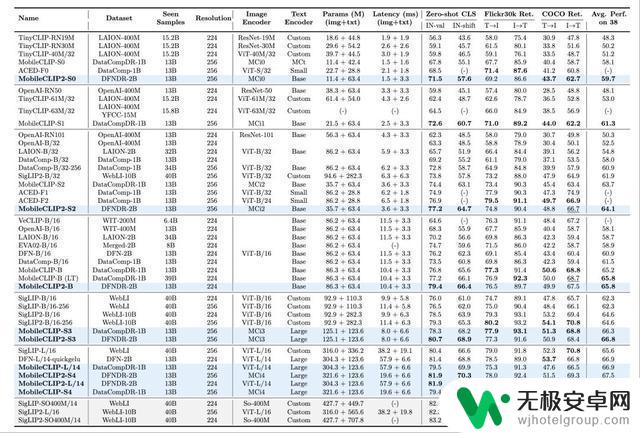
此外,这一多模态训练机制强调可复现性、可扩展性。目前,MobileCLIPS2的所有模型变体的预训练权重均已公开,支持开发者直接部署和进行基准测试。
其强化训练的数据生成代码支持任意教师集成和分布式可扩展处理,便于开发者为进一步研究和快速原型设计定制数据集强化。
在移动端,该训练机制支持直接在移动、边缘设备上部署,实现零样本检索、分类,具有极低的延迟和内存占用;通过开放数据管道和模块化的教师、标题生成器集成,可扩展到新的模态或数据域。
02.整合教师监督模型与字幕数据提升多模态模型语义覆盖范围MobileCLIP2的多模态强化训练机制能够将来自多个来源的知识高效地蒸馏到较小的模型中,并基于基础图像-文本对进行操作。
该训练机制整合了教师监督(Teacher Supervision)与字幕数据(Caption Data),旨在训练强鲁棒和高迁移性,同时最大限度降低训练或推理过程中的计算开销。字幕数据指的是与图像、视频等视觉内容关联的文本描述信息。
其核心是通过用DFN预训练的CLIP模型替换先前的集成来改进教师监督模型,为多模态模型训练增加合成字幕,也就是图像、视频等数据的文本描述信息。
具体来看,首先更强的CLIP教师模型指的是。MobileCLIP2通过用DFN预训练的CLIP模型替换先前的集成来改进教师监督,DFN2B-CLIP-ViT-L-14和DFN2B-CLIP-ViT-L-14-s39b的组合构成了教师集成的骨干。
其背后技术细节包括,对每个教师模型独立进行对数尺度(Logits Scale)的精细调整;集成蒸馏在ImageNet-1k验证集上比单教师变体提高了高达2.8%,这证明教师信号聚合对于将强性能压缩到紧凑的学生模型中至关重要;这一精度提升使MobileCLIP2能够以更少的参数数量和延迟,实现与更大参数规模的模型性能相当或超越。
其次,字幕生成教师模型(Captioner Teachers)通过两阶段协议进行升级优化。
第一阶段研究人员在大型DFN-2B数据集上对CoCa风格的描述器进行初始再训练,以提升对图像内容的表达能力。
第二阶段是在高质量标题数据集MSCOCO-123k、MSCOCO-38k上进行后续微调,生成具有增强语义质量和多样性的合成标题。
此外,苹果研究人员的消融研究表明,在精选标题上进行微调可显著提升零样本分类和检索效果。其分析了标题生成的束搜索和采样策略,发现为每张图像生成超过1-2个标题的边际效益不明显,表明策略性多样性优于数量。
这些用于蒸馏训练的合成文本描述,提升了模型的语义覆盖范围,使得MobileCLIP2-B比MobileCLIP-B在ImageNet-1k零样本任务的准确率上提高了2.2%。
03.结语:苹果改进端侧多模态模型训练机制降低开发者部署门槛在苹果发布的论文中提到,MobileCLIP2在多模态模型训练机制上的改进。与参数高效微调、实时设备端推理以及从大型多模态教师库中进行可扩展蒸馏等正在进行的大模型发展趋势高度兼容。
同时,苹果将所有模型变体的预训练权重、数据生成代码开源,也可以帮助开发者加速实验、应用于新任务以及适应不同计算环境。
本文来自微信公众号“智东西”,作者:程茜,36氪经授权发布。









